Using Kafka with Docker: A Complete Guide Featuring Node.js Examples and a Comparison with RabbitMQ

This guide provides a comprehensive walkthrough on deploying and managing Apache Kafka using Docker, showcasing how to seamlessly integrate it into your projects with practical Node.js examples. Learn how to set up Kafka brokers, Zookeeper, and client tools within a Dockerized environment, enabling efficient messaging and streaming. The guide also includes a comparison with RabbitMQ, highlighting the differences in architecture, use cases, performance, and scalability to help you choose the right tool for your needs. Whether you’re new to Kafka or exploring alternatives, this resource ensures you’re equipped to make informed decisions.
Table of Contents
- Introduction to Kafka and Docker
- Why Use Docker for Kafka?
- Setting Up Kafka with Docker
- Basic Kafka Concepts
- Building a Node.js Application with Kafka
- Advanced Kafka Features with Examples
- RabbitMQ vs Kafka: A Comparative Analysis
- Use Cases and Best Practices
- Conclusion
1. Introduction to Kafka and Docker
Apache Kafka is a highly scalable, fault-tolerant, and distributed event streaming platform. Originally developed by LinkedIn, Kafka is widely used for building real-time data pipelines, analytics, and event-driven architectures.
Docker, on the other hand, is a containerization platform that simplifies application deployment by encapsulating applications and their dependencies into portable containers. Using Docker with Kafka makes it easier to set up and manage Kafka environments.
In this guide, we’ll:
- Set up Kafka using Docker.
- Build a Node.js application to produce and consume messages in Kafka.
- Compare Kafka with RabbitMQ, a popular message broker.
2. Why Use Docker for Kafka?
Running Kafka natively can be complex due to its dependencies and configuration requirements. Docker simplifies this by providing isolated environments, ensuring consistency across different systems.
Benefits of Using Docker for Kafka:
- Quick Setup: Prebuilt Docker images allow rapid deployment.
- Portability: Containers ensure Kafka works consistently across environments.
- Isolation: Prevents conflicts between Kafka’s dependencies and other services.
- Scalability: Docker Compose enables easy scaling of Kafka clusters.
- Version Control: Easily switch between Kafka versions by changing the Docker image.
3. Setting Up Kafka with Docker
Prerequisites:
- Docker and Docker Compose installed on your machine.
- Basic understanding of Docker commands.
Step 1: Create a Docker Compose File
Create a file named docker-compose.yml:
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
depends_on:
- zookeeperStep 2: Start the Kafka Cluster
Run the following command in the directory containing the docker-compose.yml file:
docker-compose up -dStep 3: Verify the Setup
Check if the containers are running:
docker ps You should see zookeeper and kafka containers listed.
Step 4: Install Kafka CLI Tools
Kafka’s command-line tools can be used to test the setup. Use Docker to execute commands inside the Kafka container.
For example, create a topic:
docker exec kafka kafka-topics --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 14. Basic Kafka Concepts
To use Kafka effectively, it’s crucial to understand its core concepts:
- Topics: Logical channels where data is written and read.
- Producers: Applications that publish messages to topics.
- Consumers: Applications that subscribe to topics to read messages.
- Partitions: Topics are divided into partitions to distribute load and provide scalability.
- Brokers: Kafka servers that store and serve data.
- Zookeeper: Coordinates and manages Kafka brokers.
5. Building a Node.js Application with Kafka
Step 1: Install Dependencies
Create a new Node.js project:
mkdir kafka-nodejs-example
cd kafka-nodejs-example
npm init -y
npm install kafka-node dotenvStep 2: Configure Environment Variables
Create a .env file:
KAFKA_BROKER=localhost:9092
KAFKA_TOPIC=test-topicStep 3: Implement a Producer
Create producer.js:
const kafka = require('kafka-node');
require('dotenv').config();
const client = new kafka.KafkaClient({ kafkaHost: process.env.KAFKA_BROKER });
const producer = new kafka.Producer(client);
producer.on('ready', () => {
console.log('Producer is ready');
const payloads = [
{ topic: process.env.KAFKA_TOPIC, messages: 'Hello Kafka!' },
];
producer.send(payloads, (err, data) => {
if (err) console.error('Error:', err);
else console.log('Message sent:', data);
process.exit(0);
});
});
producer.on('error', (err) => {
console.error('Producer error:', err);
}); Run the producer:
Run the producer: Step 4: Implement a Consumer
const kafka = require('kafka-node');
require('dotenv').config();
const client = new kafka.KafkaClient({ kafkaHost: process.env.KAFKA_BROKER });
const consumer = new kafka.Consumer(
client,
[{ topic: process.env.KAFKA_TOPIC, partition: 0 }],
{ autoCommit: true }
);
consumer.on('message', (message) => {
console.log('Received message:', message);
});
consumer.on('error', (err) => {
console.error('Consumer error:', err);
});Run the consumer:
node consumer.js6. Advanced Kafka Features with Examples
6.1 Kafka Streams
Kafka Streams is a library for building stream processing applications. Example:
const { KafkaStreams } = require('kafka-streams');
const config = require('./kafka-streams-config');
const kafkaStreams = new KafkaStreams(config);
const stream = kafkaStreams.getKStream('input-topic');
stream.mapJSONConvenience().filter((msg) => msg.value > 10).to('output-topic');
stream.start();6.2 Kafka Connect
Kafka Connect integrates Kafka with other systems. Example: Connecting Kafka with a database.
7. RabbitMQ vs Kafka: A Comparative Analysis
7.1 Core Differences
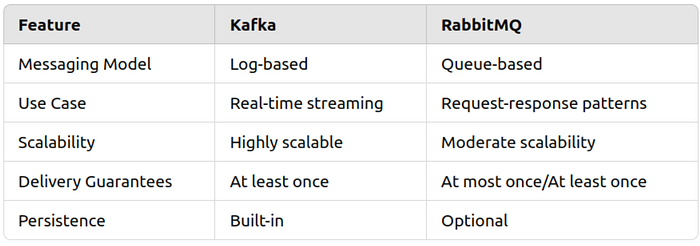
7.2 When to Use Kafka
- Event streaming pipelines.
- High throughput and low latency.
- Real-time analytics.
7.3 When to Use RabbitMQ
- Request-response systems.
- Complex routing scenarios.
- Easier setup and administration.
8. Use Cases and Best Practices
8.1 Use Cases for Kafka
- Real-time data pipelines (e.g., payment processing).
- Event sourcing for microservices.
- Log aggregation and monitoring.
8.2 Best Practices
- Partition wisely to ensure even load distribution.
- Use compacted topics for log retention.
- Monitor and tune producer/consumer configurations.
9. Conclusion
Apache Kafka, when used with Docker, simplifies the development and deployment of scalable, fault-tolerant messaging systems. By integrating it with Node.js, developers can build powerful real-time applications. While RabbitMQ remains a solid choice for traditional message queuing, Kafka excels in streaming use cases, making it indispensable in modern architectures.